

RS02-推荐系统


用户网络行为画像
James
2019-05-31
视频推荐
视频推荐系统根据用户的历史行为数据和视频的内容特征数据进行挖掘与分析,构建出用户画像和视频的物品画像,同时利用上下文信息,对用户为来选择行为做出预测,完成对用户的Top N推荐。
常见的推荐算法
常见的推荐算法根据使用数据源的不同可以大致分为三类:
- 协同过滤的推荐方法
- 基于内容的推荐方法
- 基于知识的推荐方法
推荐系统的测评方法
推荐系统的测评过程可分为离线(Offline)测评,用户调查(User Study)和在线(Online)测评三个阶段。
常见的推荐系统评测指标有:
- 点击率和转化率(CTR & Conversion Rate)
- 用户满意度(Guest Satisfication Index)
- 预测准确度(Prediction Accuracy)
- 覆盖率(Coverage)
- 多样性和新颖性(Diversity & Novelty)
- 适应性和扩展性(Adaptivity & Scalability)
协同过滤的推荐方法
协同过滤 (Collaborative Filtering, CF)
基于"跟你爱好相似的用户喜欢的东西你可能也会喜欢"这一思想。
- 基于记忆的推荐算法
- 基于用户的协同过滤推荐算法(User-Based):找到与目标用户相似的用户群,推荐他们评价高的物品
- 基于物品的协同过滤推荐算法(Item-Based):维护一个物品相似度矩阵,推荐与目标用户评分高的物品相似的物品
- 基于模型的推荐算法:使用机器学习模型来辅助推荐
- 隐因子模型
- 朴素贝叶斯
协同过滤推荐方法的局限性:
- 无法对新用户新物品做出推荐(冷启动问题)
- 无法一句物品深层特征和属性来推荐
- 受到用户打分稀疏性问题的约束
- 当用户和物品数量变大时,计算量变大
关系矩阵
以视频推荐为例,我们需要维护三种生态关系,分别为:用户关系矩阵(U-U矩阵)、视频关系矩阵(V-V矩阵)和用户-视频关系矩阵(U-V矩阵)。
U-U矩阵
用户相似度的常用方法有Pearson相关系数、余弦相似度、修正的余弦相似度、Spearman秩相关系数和均方差等。其中Pearson相关系数(Pearson Correlation Coefficient)表现要优于其他方法。
Pearson相关系数用于度量两个变量 $i$ 之间 $j$ 的相关性,取值范围为 $[-1,+1]$。$[+0.6,+1]$ 可被视为强正相关,$[-1,-0.6]$ 被视为强负相关。其计算公式为
$$\text{sim_user_value}(i.j)=\frac{\sum{c\in I{ij}}(r_{i,j}-\bar{ri})(r{j,c}-\bar{rj})}{\sqrt{\sum{c\in Ii}(r{i,c}-\bar{ri})^2}\sqrt{\sum{c\in Ij}(r{j,c}-\bar{r_j})^2}}$$
其中, $I{ij}$ 为用户 $i$ 和用户 $j$ 共同评价过的视频的合集,$c$ 是这个集合中的视频元素,$r{i,c}$ 表示用户 $i$ 对视频 $c$ 的评价值,$\bar{r_i}$ 表示用户 $i$ 对视频的平均评价值。
算法流程:
- 获取用户与视频评分的数据
- 分别计算每个用户对所观看视频的平均评价值 $\bar{r}$
- 对于 $n$ 个用户,依次计算第1个用户与其余 $n-1$ 个用户的相似度,第2个用户与其余 $n-2$ 个用户的相似度...
- 对于两个用户 $i$ 和用户 $j$
- 查找两个用户共同评价过的视频集合 $I_{ij}$
- 计算用户 $i$ 和用户 $j$ 的Pearson相关系数
- 存储相应数据
V-V矩阵
我们使用余弦相似度来计算视频的相似度。余弦相似度绝对值的取值范围在 $[0,1]$ 之间,夹角越小,余弦相似度的值越大,两个视频更为相似。
$$\text{sim}(\textbf{x}_i,\textbf{x}_j)=\cos(\textbf{x}_i,\textbf{x}_j)=\frac{\textbf{x}_i\cdot \textbf{x}_j}{||\textbf{x}_i||_2\times||\textbf{x}_j||_2}$$
考虑到用户评分标准的偏差,我们通常会减去用户对物品的平均评分来对余弦相似度进行一定的修正。修正后的余弦相似度为
$$\text{sim}(\textbf{x}_i,\textbf{x}j)=\frac{\sum{u\in U}(R_{u,\textbf{x}_i}-\overline{Ru})(R{u,\textbf{x}_j}-\overline{Ru})} {\sqrt{\sum{u\in U}(R_{u,\textbf{x}_i}-\overline{Ru})^2} \sqrt{\sum{u\in U}(R_{u,\textbf{x}_j}-\overline{R_u})^2}}$$
存疑?
算法流程:
- 获取用户与视频评分的数据
- 分别计算每个用户对所观看视频的平均评价值 $\bar{r}$
- 对于 $n$ 个视频,依次计算第1个视频与其余 $n-1$ 个视频的相似度,第2个视频与其余 $n-2$ 个视频的相似度...
- 对于两个视频 $i$ 和视频 $j$
- 查找同时评价过两个视频 $i$ 和视频 $j$ 的用户群 $U_{ij}$
- 计算视频 $i$ 和视频 $j$ 的修正后的余弦相似度
- 存储相应数据
U-V矩阵
U-V矩阵表示了用户与视频之间的关系,可以是评分或者是否观看过该视频。常见的U-V矩阵是用户对视频的评分矩阵。
U-V矩阵的行列数会随着用户数量增大或者视频增多而变得十分巨大,由于用户只会对一部分视频进行评分,所以U-V矩阵通常会十分的稀疏。为加快计算时间,我们通常需要对高位的矩阵进行有效的降维,常用的降维方式有奇异值分解(SVD)和主成分分析(PCA)
奇异值分解(SVD)
将给定的矩阵分成三个矩阵相乘的形式,即 $$ \textbf{M}{m\times n} = \textbf{U}{m\times m}\Sigma{m\times n}\textbf{V}{n\times n}^T $$ $\textbf{U}$ 和 $\textbf{V}$ 分别称为左右奇异矩阵,其本质是酉矩阵。 $\Sigma$ 为对角矩阵,其对角线上的值几位矩阵 $\textbf{M}$ 的奇异值。
矩阵 $\Sigma$ 中的奇异值 $\sigma$ 是从大到小排列的,我们可以用前 $n$ 个奇异值来近似表示矩阵。
在推荐系统的应用中,SVD能将一个稀疏的评分矩阵分解为一个表示用户特征的矩阵 $\textbf{U}$ 和一个表示物品特征的矩阵 $\textbf{V}$,以及一个表示用户和物品相关性的矩阵$\Sigma$。
主成分分析
PCA能够有效的找到数据中的主要成分,去除噪音和冗余。
最近邻居算法
最近邻居算法(k Nearest Neighbors, kNN)是最经典也是最重要的基于记忆的协同过滤算法。
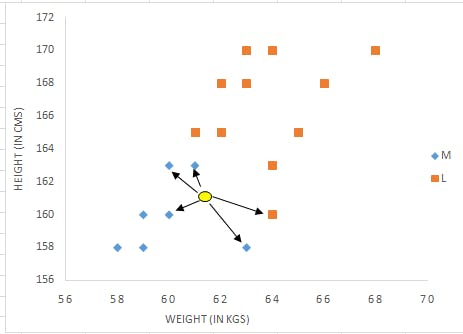
主要流程:
- 计算每一对用户之间的相似度,将相似度高的用户作为邻居
- 依据所有邻居的相似度在某一个项目上做加权和,获得预测用户对该项目的分值
| 优势 | 劣势 |
| 实现简单,推荐精度高 | 对数据稀疏性敏感,可扩展性不强 |
基于用户的协同过滤算法
基于用户的协同过滤算法(User-Based CF)
我们可以通过下式计算用户对视频的喜好程度: $$ p{uj}=\frac{\sum{N_i\in N(u)}\text{sim}(u,Ni)\times r{Ni,j}}{\sum{N_i\in N(u)}\text{sim}(u,Ni)} $$ 其中,$p{uj}$ 代表用户 $u$ 对视频 $j$ 的喜爱程度,$r_{N_i,j}$ 表示用户 $N_i$ 对视频 $j$ 的评价,$\text{sim}(u,N_i)$ 代表用户 $u$ 和用户 $N_i$ 的相似程度。
算法流程:
- 获取近期变化的用户ID集合 $U$
- 针对集合 $U$ 中的每个用户 $u$:
- 访问用户相似矩阵,获取与用户 $u$ 相似的用户集合 $N(u)$
- 针对 $N(u)$ 中的每一个用户 $u_i$:
- 获取与用户 $u_i$ 有关联的视频集合 $M(u_i)$
- 针对视频集合 $M(u_i)$ 中的每个视频,计算用户偏好值
- 对 $M(u)$ 中所有视频进行按照用户偏好值进行加权、去重、排序
- 取Top-N个视频,并赋予解释
- 推荐Top-N
基于用户的协同过滤(User-Based CF)适用于用户交互性强或者用户量相较视频数量变化稳定的视频网站。
基于物品的协同过滤算法
基于物品的协同过滤算法(Item-Based CF)
视频相似度一般采用修正后的余弦度计算公式 $$ \text{sim}(j,i)=\frac{ \sum{u\in U}(M{u,i}-\bar{Mu})(M{u,j}-\bar{Mu}) }{ \sqrt{\sum{u\in U}(M_{u,i}-\bar{Mu})^2} \sqrt{\sum{u\in U}(M_{u,j}-\bar{Mu})^2} } $$ 其中,$M{u,i}$ 表示用户 $u$ 对视频 $i$ 的评分,$\bar{M_u}$ 代表用户 $u$ 对其观看过的所有的视频的平均打分。
用户对视频的喜好程度可用下式计算 $$ r{uj}=\frac{ \sum{j\in N(u)}\text{sim}(j,i)r{ui} }{ \sum{j\in N(u)}\text{sim}(j,i) } $$ 其中 $r{uj}$ 代表用户 $u$ 对视频 $j$ 的喜好程度,$r{ui}$ 代表用户 $u$ 对视频 $i$ 的偏好程度,$\text{sim}(j,i)$ 代表视频 $i$ 和视频 $j$ 的相似度。
之后根据 $r_{uj}$ 对视频进行排序,选择分值高的视频。
算法流程
- 获取最近浏览过视频的用户合集 $U$
- 针对集合 $U$ 中的每个用户 $u$:
- 获取该用户最近观看的视频合集 $M(u)$
- 访问视频相似矩阵,获取与 $M(u)$ 相似的视频集合 $N(u)$
- 针对 $N(u)$ 中的每个视频,计算用户偏好值
- 依据偏好值,对 $N(u)$ 的视频进行排序
- 取Top-N个视频,并赋予解释
- 推荐Top-N
基于物品的协同过滤(Item-Based CF)适用于视频数量较为稳定的场合。
基于隐因子模型的推荐算法
基于隐因子模型(Latent Factor Model based, LFM-based)
将用户和视频投影到人抽象出来的隐因子空间中,根据用户和视频在隐因子空间中的距离来寻找可推荐的视频,将与目标用户距离近但是还未被用户接触过的视频推荐出来。
基于隐因子模型的协同过滤推荐,用户对视频喜好的评分计算方式为 $$ r_{ui}=\textbf{P}_u^T\textbf{Q}i=\sum{k=1}^Kp{uk}q{ki} $$ 其中 $r{ui}$ 代表用户 $u$ 对视频 $i$ 的评分,$p{uk}$ 度量了用户 $u$ 的兴趣和第 $k$ 个隐类的关系,$q_{ki}$ 度量了视频 $i$ 和第 $k$ 个隐类的关系。
推荐系统的用户行为分为显形反馈和隐形反馈两种,显形反馈是用户对视频打分,隐形反馈是用户的观看浏览行为。
对于隐形反馈数据集,数据集中只有正样本而没有负样本(用户不感兴趣的视频),因此要进行负样本采样。负样本采样通常要遵守以下两个原则:1. 保证正负样本的数量均衡,2. 要选取热门的但是用户没有行为的视频作为负样本。
构造好训练及后,我们需要优化如下损失函数来找到最合适的参数 $p$ 和 $q$。 $$ Loss = \sum(r{ui}-\sum{k=1}^Kp{uk}q{ki})^2+\lambda(||p_u||^2+||q_i||^2) $$
算法流程
- 获取最近浏览过视频的用户合集 $U$
- 针对集合 $U$ 中的每个用户 $u$:
- 获取该用户最近观看的视频合集 $M(u)$
- 从基于隐因子的视频相似矩阵中获取与 $M(u)$ 相似的视频集合 $N(u)$
- 针对视频集合 $N(u)$ 中的视频,计算用户的偏好值
- 依据偏好值进行排序
- 取Top-N个视频,并赋予解释
- 推荐Top-N
基于朴素贝叶斯分类的推荐算法
推荐系统可以被视为一种分类问题。
贝叶斯定理的作用是在已知 $P(A|B)$ 的情况下球的 $P(B|A)$,其计算公式为 $$ P(B|A)=\frac{P(A|B)\times P(B)}{P(A)} $$
朴素贝叶斯分类适用于数据量不大,类别较少的分类问题。
基于内容的推荐方法
基于内容 (Content-base, CB)
基于"用户喜好较为稳定"这一思想。
首先需要根据用户历史行为数据构建用户画像(User Profile),代表用户的行为偏好;同时需要分析提取物品的内容特征来建立物品的物品画像(Item Profile),在得到了用户画像和物品画像后,通过相似度比较来做出推荐。
- 基于信息检索的启发式算法:TF-TDF
- 基于机器学习的自适应算法
不存在视频冷启动的问题,能够给出视频特征作为推荐理由。
基于内容的推荐方法的局限性:
- 难以获取视频特征,视频标注工作量巨大
- 用户画像建立需要大量用户数据
- 难以为用户发现新的兴趣
基础的CB推荐算法
将视频的固有属性提取成向量,从用户的过往行为中获取用户内容偏好,计算余弦相似度。
新老视频被推荐的可能性相同。
基于TF-TDF的CB推荐算法
基于TF-IDF的CB推荐系统会从用户的评论中获取有关信息。TF-IDF是自然语言处理中长哟个的计算文档中词或短语的权值的方法,是词频(Term Frequency, TF)和逆转文档频率(Inverse Document Frequency,IDF)的乘积。
假设文档集包含 $N$ 个文档,其中包含关键词 $k_i$ 的文档数为 $ni$。 $f{ij}$ 表示关键词 $k_i$ 在文档 $dj$ 中出现的次数,$f{dj}$ 表示文档 $j$ 中出现的词语总数。
$k_i$ 在文档 $dj$ 中的词频 $TF{ij}$ 定义为: $$ TF{ij}=\frac{ f{ij} }{ f_{dj} } $$ IDF是词语普遍性的度量,我们记IDF计算方式为: $$ IDF_i=\log(\frac{N}{ni}) $$ 则TF-IDF为: $$ w{ij}=TF_{ij}\times IDFi=\frac{f{ij}}{f_{dj}}\times\log(\frac{N}{n_i}) $$
基于kNN的CB推荐算法
与基于kNN的CF推荐算法比较相似,区别在于,基于kNN的CF算法根据用户对物品的评分来计算物品间相似度,然而基于kNN的CB推荐算法根据物品画像来计算物品间相似度。
相似度计算可以使用杰卡德距离,余弦相似度或是Pearson相关系数。
CB和CF推荐方法的优劣比较
| 基于内容(Content-Based) | 协同过滤(Collaborative Filtering) | |
| 用户间独立性 | 强 | 弱 |
| 推荐结果的可解释性 | 强 | 弱 |
| 新物品的冷启动问题 | 容易解决 | 难以解决 |
| 物品的特征提取 | 需要考虑且提取困难 | 无需过多考虑 |
| 用户潜在兴趣的挖掘 | 难以实现 | 容易实现 |
| 新用户的冷启动问题 | 难以解决 | 难以解决 |
基于知识的推荐方法
基于知识 (Knowledge-based, KB)
通过交互等方式直接获取用户的需求,然后根据物品进行匹配。
- 基于约束(Constraint-Based)的推荐算法
- 基于实例(Case-Based)的推荐算法
不存在用户冷启动的问题,能够很好的给出视频推荐理由。
基于知识的推荐方法的局限性:
- 知识获取困难
- 用户必须先说明需求才能够推荐。
视频推荐评测
推荐系统评测实验方法可分为用户调查,在线测评和离线测评三种方式。 |测评方法|优点|缺点| |--|--|--| |用户调查|可以直接得到用户满意度|没有准确度等指标,不宜大规模开展| |在线测评|数据真实、测评标准直观|成本高,试验结果不可解释性、周期长、需要大量用户| |离线测评|低成本、指标可解释|数据稀疏性,指标不直观|
A/B测试(A/B Test)
- 同时运行两个或两个以上方案
- 两个方案只有一个变量不同,其他条件均相同
- 有明确的评价指标用于评价方案优劣
- 测试过程中,同一用户从始至终都应只接触一个方案
A/B测试主要测评指标:点击率;转化率。
离线测评标准
- 准确度
- 评分准确度
- 预测评分准确度:平均绝对误差(Mean Absolute Error, MAE),MSE,NMAE...
- 预测评分关联度(预测评分和真实评分趋势相同):Person积距相关,Spearman相关方法,Kendall's Tau相关方法
- 排序准确度
- 排序准确度
- 平均准确度指标(Mean Average Precision, MAP)
- NDCG(Normalized Discounted Cumulative Gain)
- 分类准确度
- 分类准确率指标(Percision)
- 分类召回率指标(Recall)
- F指标
- AUC指标
- 评分准确度
- 多样性指标
- 覆盖率
- 多样性和新颖性